Edit (24 Nov 2021):
- Hackernews link here
- Add "and the Other Way Around" to the title to avoid causing cognitive dissonance. "Don't Bring a Tree to a Mesh Fight" bring about a feeling that mesh-like patterns are favored over tree-like patterns. The actual point of this article are 1.) mesh-shaped patterns are significantly more complex than a tree-shaped patterns and should be avoided whenever possible 2.) solutions for tree-shaped problems does not elegantly solve mesh-shaped problems, and vice versa.
- Each node can only be passed at least once -> Each node can only be passed at most once.
- The possible number of calls to
cis zero to infinity -> The possible number of calls tocis zero to one
Edit (3 June 2022):
- Grammar and typo fixes
Examining control flow and architecture in the form of graphs yields insight into complexity.
Today, JavaScript runs everywhere, browsers, natively, you name it. Take a time to scrutinize what it takes to run JavaScript. There is a lot to appreciate in the process. An enormous chunk of hidden mechanisms works to support JavaScript. The same mechanism keeps the runtime from accidentally corrupting the music you're playing in the background.
The engine that runs JS code is a Turing complete one, as in, even though JS is not a whole computer, it can do what a computer does, albeit not as fast. Features in JS, such as garbage collection, event-driven programming, Timer functions, async function, and so on, are powered by JavaScript engine's event loop.
The event loop is convenient confinement. JS VM and similar VMs, like Python and Java, enjoy the same protection. Other examples: OS kernel guarding the user space, GC guarding against memory leak, and popular game engines saving your time from having to deal with "the main loop".
Control Flow Graph.
Graph theory is all about nodes connected by edges. When the edges have direction, it is called a directed graph (digraph for short). Graph theory is pretty generous. It can represent various things: networks, mathematical functions, you name it. Control flow graph is one variant that represents operations and jumps in-between nodes and edges, respectively.
Directed Acyclic Rooted Tree is a graph that has one root node and all edges point away from the root. Look at the code below.
a();
if (x) b();
else c();
That code, when represented as a control flow graph, looks like this.
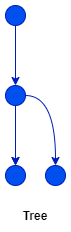
It is in the shape of a Directed Acyclic Rooted Tree or simply a tree. The neat thing is, that a tree-shaped computation is always "one-pass". Each node can only be passed at most once.
If a loop is introduced into the sequence, this happens:
// The psudocode
a();
loop {
b();
if(y) {
c();
break;
} else {
d();
}
}
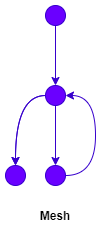
If the break-from-loop condition is unknown, here's the fact.
- The possible number of calls to
ais one; - The possible number of calls to
bis one to infinity; - The possible number of calls to
cis zero to one; - The possible number of calls to
dis zero to infinity.
So, if you list all the possible sequences that can happen in this program:
- the loop happens once
- the loop happens twice
- the loop happens three times
- ... and so on and so on
The total possible combination of the overall sequence is infinity. Now infinity is not a concept we underestimate. Infinite possibilities make it infinitely hard to predict if the program will end eventually. You won't know if the program will end eventually. You won't know if you will exit the deadly jungle until you find the way out of it. This is the infamous halting problem.
Mesh is simply a different beast.
The Enigmatic Guardian
Alice has a JavaScript script. Inside it is a function that contains an infinite loop. Alice opens a tab in her favorite browser, and then the development tool. Alice then runs the function on it. The console freezes, but the browser does not. Alice freaks out from the freezing tab, she closes it. The browser waits idly for a while then proceeds to close the tab. Alice is relieved. "It's not so bad", Alice thought. Alice lives in the real world. The real world owns the computer, which in turn owns the browser, which in turn owns the tab, which in turn owns the JavaScript runtime. Alice can just click the close-tab button because Alice owns it.
Imagine if there's a life-form living inside the JavaScript world, this creature, due to the infinite loop, is having a bad day. Let's call this creature Bob. Bob is stuck! The JavaScript engine that is supposed to enable Bob to do his daily activity is now swamped by a continuous stream of instructions due to the infinite loop. How would he escape from that world that's suddenly invaded with an infinite loop? How would he escape from the jungle? There is no way! He does not have a close button. He does not know what a tab is, nor the JavaScript runtime, because he is limited by it. He might speculate he is living in a simulation, but he won't know unless somebody from the outside tells him so. What Alice views as a temporary moment of panic is beyond the whole life of Bob. When the tab is not, Bob is not.
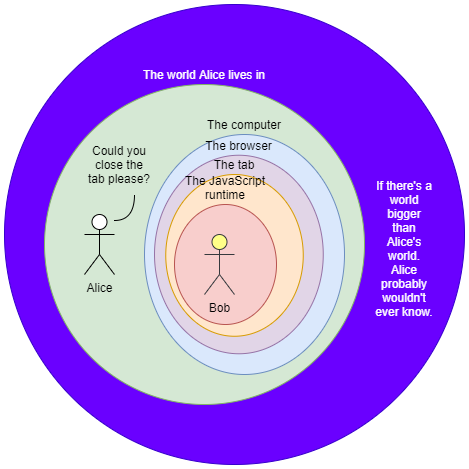
This is the enigmatic guardian, Bob's enigmatic guardian. It protects the space and the time of what is living inside it. It encapsulates all of it. It protects the time and the space of what is living inside it. When necessary, it opens a hole in the boundary for the beings that live inside to interact with what is outside, but never complete freedom. Other times, the guardian (or the guardian's guardian) gets careless and it opens up unintended holes.
The world on the inside might see this:
a();
b();
loop {
c();
}
But the enigmatic guardian foresee.
exit_signal = false;
code = code_runner.new(
`
a();
b();
loop {
c();
}
`
);
exec_both([
|| {
loop {
if exit_button.is_pressed {
exit_signal = true;
break;
}
}
},
|| {
loop {
code.step_through();
if exit_signal == true || code.remaining() > 0 {
break;
}
}
}
]);
Upon seeing this, you exclaim: "You can actually beat the halting problem! The simulation will always actually exit!" Yes, but only if you own the simulation, not when you're living inside it. Would you know if you live inside a simulation? Not unless the container of the simulation leaks information inside, either deliberately or indeliberately.
A loop is once again involved. The enigmatic guardian needs to guard its simulation inside a loop. It needs to switch between the execution of the simulation and the guarding function. More loops, more mesh. Simulation costs a lot.
Side Story: Lifetime
The simulation parable tells us one thing. The simulation's lifetime never exceeds its enigmatic guardian's. The simulation is always born after the existence of its guardian, and it always dies before its guardian does. The guardian needs to live long enough to protect the simulation's boundary during the simulation's lifetime.
But, it turns out not everything has to be a simulation. In fact, running a simulation is very, very costly. Look at this.

6.1MB is not much, but it's not too little either. This little is not doing anything at the moment and it is consuming that amount of space in my memory.
Encapsulation pattern is predominant in computer programs. Managing objects and allocated memory is one of them, but we don't have the luxury to have every module, every function, and every object in a program actively guard the boundary of the objects it owns. Ain't nobody got time for that. Therefore, a program, which is usually encapsulated inside a process, which in turn is managed by the OS, usually has at most one entity that guards the boundary and the lifetime of objects inside it. Usually, this comes with the language and/or the runtime.
The old way is for the programmer to manually inspect and delete objects that are out of scope or unused. The modern way that has been popular for a couple of decades is to have a GC, at intervals catching objects that are not owned anymore. But here's a genius method: Actively letting the programmer know that a certain object is past the lifetime of the owner while the program itself is being written. It is working by the basic principle that an owned entity must not live longer than its owner and then enforce the code work that way on compile time. Therefore, keeping objects in check at runtime requires only a minuscule amount of space and time. Sadly, I've yet to work on a meaningful project using that language.
Mesh is just a different beast, both in the eyes of Time or Space
We've talked about execution sequence, the order of happenings seen when we are transitioning across the dimension of time. At tick 0 a() happens, at tick 1 b() happens, at tick 2 c() happens, and so on, and so on. A loop is a mesh that is stretching across the time dimension. A loop in space is not less complicated than a loop in time.
Take pathfinding for example. There are a couple of connected nodes. These nodes and edges are enclosed in a system you own. Each node has an alphabetic label, and each connection has a weight.
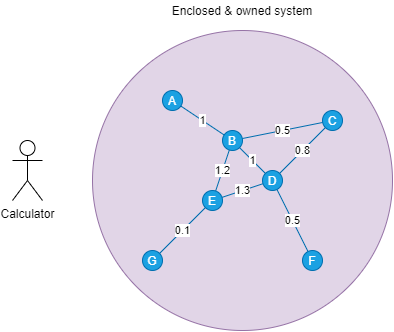
You are the calculator. You have this problem: you need to find the path from A to F that has the least weight. The answer? Since this system is a system you own, it's relatively simple. You have all the numbers. You don't want to think too hard and choose the dumbest way: list all routes, from A to F, and calculate and compare the weights.
Because you own the whole mesh, you know roughly the cost of your solution in the worst case: 7 nodes labeled by a char, 6 edges, assuming all nodes are connected, run a 7 permutation 6 = 504, 5040 possibilities. 5040 * 7 (number of nodes) * 1 byte (size of char) for storing the sequences plus 5040 * 4 bytes for each byte (we can use int, which is 4 bytes each), that is 25 kilobytes. Plus a few more kilobytes for the program's stack. Slab a 1-megabyte of memory and your program is ready to go.
You can also calculate how long your program will take at most with those numbers.
Now, a real mesh!
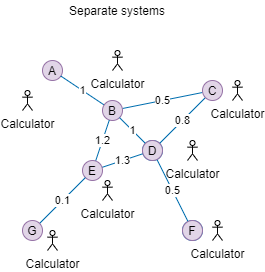
A real mesh in the real world. This mesh is sitting in the same layer as you, the calculator. It is not in an enclosed system. You don't have all the numbers. A only knows it is connected to B, but A, in the beginning, does not know what nodes B is connected to. How is the same problem solved: the cheapest path from A to F?
The first step, knowing the number, needs everyone on the same page on what they are doing. When A asks B, what is the fastest route to F, B needs to speak the same language, and so do C and D, .... Everyone must know a particular protocol for it and have a program installed to work on that protocol. That means going over a different geographical location and installing it there.
Contacting neighbors recursively is more costly than A* or Dijkstra's Algorithm both in CPU time and memory space. Therefore it might be a good time to use a cache, we can reuse what we previously calculated! Also. we are introduced to one of the hardest computing problems: cache invalidation. If the mesh can change over time, either the weight or the connection, when are we going to invalidate the cache? Just pick a number and hope for the best!
Resource calculation is also infinitely harder. Since A does not know the whole topology, how would A know how much RAM is needed to run the protocol? Simple, it does not know. One just needs to install the RAM with a size that makes sense and hopes for the best. Since A also does not know the maximum number of nodes involved in the mesh, it might be best for the program to have a least-recently-used cache invalidation mechanism.
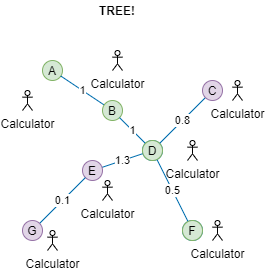
In contrast, if we can assume the network is always in the form of a tree, life will be a lot simpler!
Functional Programming Easier to Reason About than OOP?
A controversial topic!

Source: https://knowyourmeme.com/photos/130-disaster-girl
Whole FP vs OOP is just about this tree vs mesh.
- OOP's first iteration was about cell-to-cell-like interactions, such as data encapsulation, and asynchronous messaging, essentially about living in a mesh and as a part of it. Later on, the meaning of OOP is overloaded into what Java has become, springing up the four pillars, encapsulation, abstraction, polymorphism, and inheritance (the last is more often counter-productive than productive). OOP paradigm and language have primitives to encapsulate (protect internal data), and abstract it. The abstractions are polymorphic to be able to talk to many kinds of foreign instances with the same abstracted interface. As for the scope of what's being encapsulated and abstracted, it is up to the architect of the software.
- On the other hand, FP's principles are all about writing in a program in the shape of a tree. If you pay attention to the FP principles, immutability, referential transparency, zero side effect, they are about scoping and owning expressions, reducing branches, and pulling branches (errors are branches too) into the early stage of a software lifecycle (compilation step). Every FP language is designed to essentially shape the timeline into a tree as best as it can, and reduce branches as best as it can.
- If you are writing a program that lives inside a mesh, OOP is the way to look at the world.
- If you put some functions together in an enclosed system where there is no outside interference, FP is a really neat tool.
There are millions of diss tracks between FP vs OOP laying on the interweb. But contrary to that fact, the two are NOT MUTUALLY EXCLUSIVE. The two are paradigms that birth various features in programming languages. These features are to be used wisely. These features are not a subject of zealotry, which results in bad patterns:
- OOP paradigm, when used to compose small components into a set of tightly related systems that are not even running concurrently, is a suicide. Over abstraction and over encapsulation is expensive and make the code hard to restructure.
- Pipe syntax can be weird to tell a story that is easier done imperatively, e.g:
- Good: raw input, decode_or_error, validate_or_error, fold(store_data, show_error)
- Bad: Peter, bitten_by_spider, fallen_asleep, got_power
Just don't bring a tree to a mesh fight, and vice versa!
Rearchitecting Complex System
Another popular topic of debate is monolithic vs microservice architecture. Negative opinions of microservices/monolith are often rising from a one-sided story where the cons of microservices/monolith are overpowering the pros in a single instance. Most often discussion about it doesn't end in one side winning. Most articles on the interweb conclude the battle with the pros and cons of monolithic and microservices on a very generic and vague level. It was never a win-win battle in the first place.
Those people are fighting complex systems and the key to solving the puzzle is to look into it in detail. A complex system is a system composed of many components which MAY interact with each other. The keyword is MAY.
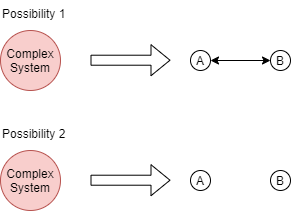
If you break down a complex system into two smaller components: there are two possibilities.
-
the two components interact with each other,
-
the two components don't.
This can be made more detailed by adding direction, making it 4 possibilities:
- component A and component B do not interact
- component A sends signals to component B
- component B sends signals to component A
- component A and component send signals to each other
But let's just use the bidirectional version all the time. This is how it looks to break down a complex system into two smaller components.
3 COMPONENTS:
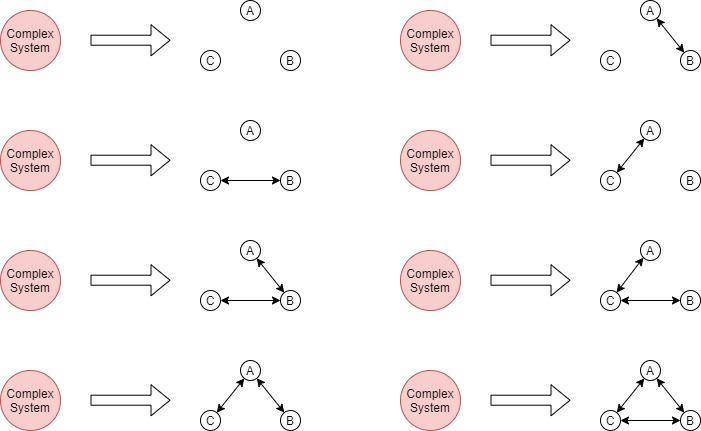
And so on. But my point is the keyword is in MAY. And the inverse is similar too. Two or more components can either merge or not depending on if merging is relevant for the purpose of the system owner.
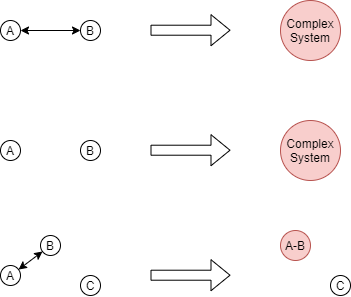
What does merging/splitting stand for? It can represent many things! In the case of monolithic vs microservice, the merging/splitting stands for:
- The code structure or the repository where the code of the two or more components is stored
- The runtime separation: in monolithic a bulk of code is loaded into a single process that runs as a server acting as all the components into one, in microservices, different components reside as different processes and each is hosted on different machines with different addresses.
In the other case, for example, company organization the splitting/merging may stand for the adjustment of the number of administrative tasks that need to be done in order for two components to interact with each other, or what people like to name: the bureaucracy. This relates to microservices vs monolithic, in the sense that inter-component communication of microservice - inter-component communication of monolithic = an HTTP request. (Except when the monolithic is code-only, e.g. PHP, where every HTTP request handler is an isolated process).
Obviously, the first step of designing a complex server-side application, an organization structure, or a network topology, is to determine the interdependence of the components. Draw a diagram of it. I'll help determine which components must be grouped and which shouldn't. Below is an image of a complex system with variations of pink backgrounds. The darkest pink represents A as a group; The next darkest represents, A, B, and I as a group; And so on. A tree is very flexible in variations.
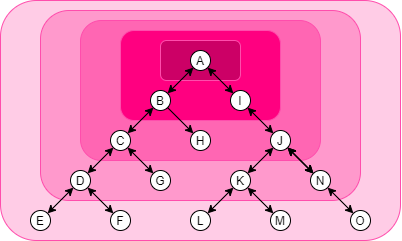
This system is a tree. You can treat any nodes as the root and then increment the size of the scope from that root.
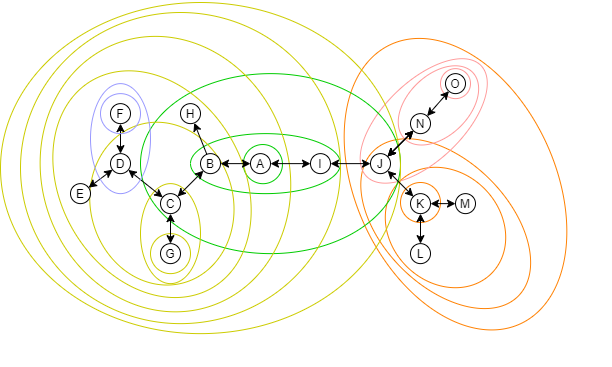
A complex system with meshes, though, needs more care when you're merging and splitting. Nodes that are joined into a mesh are usually more tightly coupled than the other. Should a "community" build up from the nodes, it should be the group with mesh first.
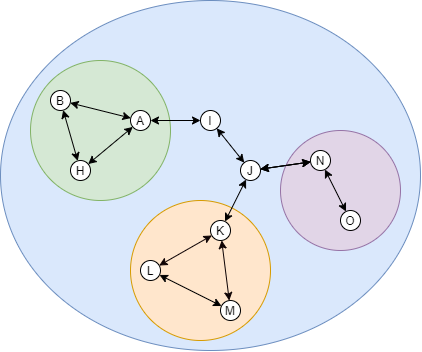
If this rule is broken, then the link inside the mesh will be disrupted, causing the whole system to not work as effectively as it potentially does.
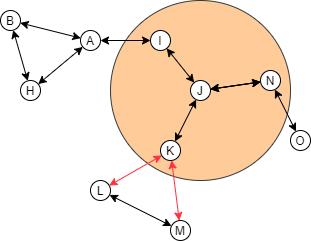
This mesh link breaking might be too vague without a real-world example. So here's one:
Problem Example
Three groups of engineers, frontend, backend, and infra are working on an application. Each group has its own component to maintain. A PM is assigned to supervise the three groups.
Problem: The PM sets up a separate meeting with each group. When a group is blocked, the group initiates communication through the PM. The PM then relays it to the other group. Now the PM is the middleman, it makes the PM a communication bottleneck. The condition is frustrating the PM, not to mention that the content of the message relayed by PM is heavily technical.
Diagram representation:
- A node represents the group: frontend, backend, infra, and PM
- The link between two nodes represent the subject that needs to be discussed in the link: frontend and backend discuss the contract needed for both component to communicate at run-time
- Grouping represents the enabling of formal communication channels: PM establishes a meeting for each group, PM-frontend, PM-backend, PM-infra.
- The broken link represents the inefficiency caused by the wrong way of grouping: PM has to relay messages from frontend-backend, frontend-infra, and backend-infra.
Solution: After three days, the PM notices that the setup is not efficient. What the PM needs from the developer groups is high-level information, e.g. task estimation, or sprint goal. The engineers-to-engineers discussions are mostly about technicalities, which only need to be reported to the PM less frequently. The PM then reshapes the group into one big group by creating a channel for all three groups to discuss technical stuff. PM only sometimes watches the conversation since what matters to the PM about technicalities is only transparency, not actuality. Soon the PM found that not being a middle-man between the engineers makes the whole process more productive.
Whenever Possible Make a tree
If a tree is impossible, make a non-cyclical mesh.
Once upon a time my colleagues and I needed to add a "login-with-identity-provider" feature to our app. Let's just call the app Canihas. We slapped some OAuth in there. It wasn't complex. We had a server and a website. However you think about it, on the surface level, the server and the website is of one whole. We made the flow of the transaction like the image below:
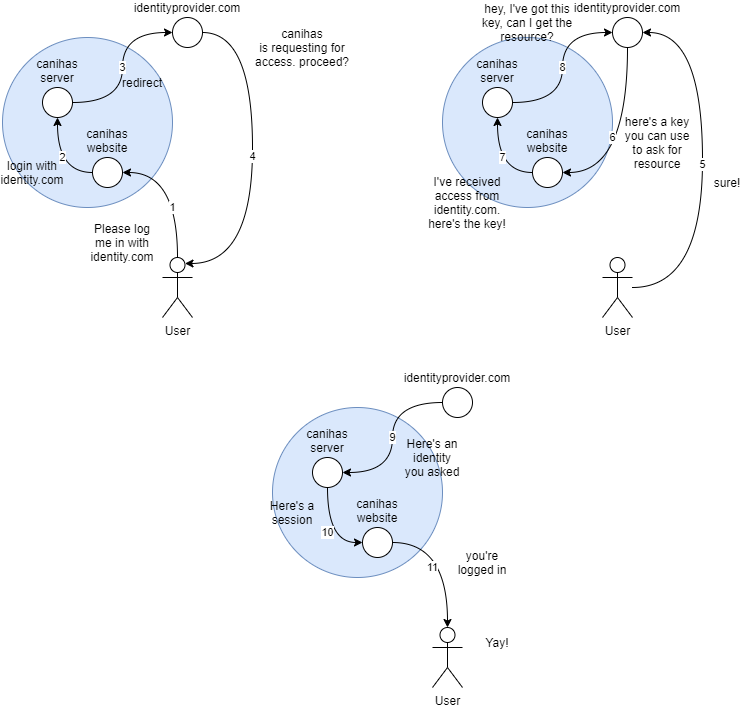
Step 1-3: The user asks for "Login with Identity Provider" via Canihas, which is passed by Canihas' website, to Canihas' server, to the Identity Provider.
Step 4-5: The Identity Provider asks the user if Canihas can have their consent to access some data in Identity Provider, and the user agrees.
Step 6-8: The identity Provider gives an[ ](https://www.oauth.com/oauth2-servers/server-side-apps/authorization-code/#:~:text=The authorization code is a,approve or deny the request.)authorization code to the website, which then is passed to the server, which is then used to ask Identity Provider for some information about the consenting user.
Step 9-11: Long story short the server got the information, use it to create an account or log the user into one, and pass the session down to the website and the user.
The flow was correctly implemented, but it caused some problems. If you notice, the authorization_code goes through the website, to the server, and then back to the Identity Provider again. Why do we design it this way? It was because the website store a certain value in the local storage that is needed by the server to map which request matches the authorization_code. The Identity Provider OAuth client configuration is set to redirect to the website to retrieve this value.
This creates a mesh. What's wrong with this mesh, though? Since the website is involved in the authorization_code flow, it MUST know that it will receive an authorization code, it also MAY know that the authorization_code request can fail, therefore we implemented a handler for it, bypassing the server for error handling. This creates unnecessary complexity because both server and website must have a piece of code to support the authorization flow.
So we decided to simplify this. We got rid of the mesh and turned it into a tree.
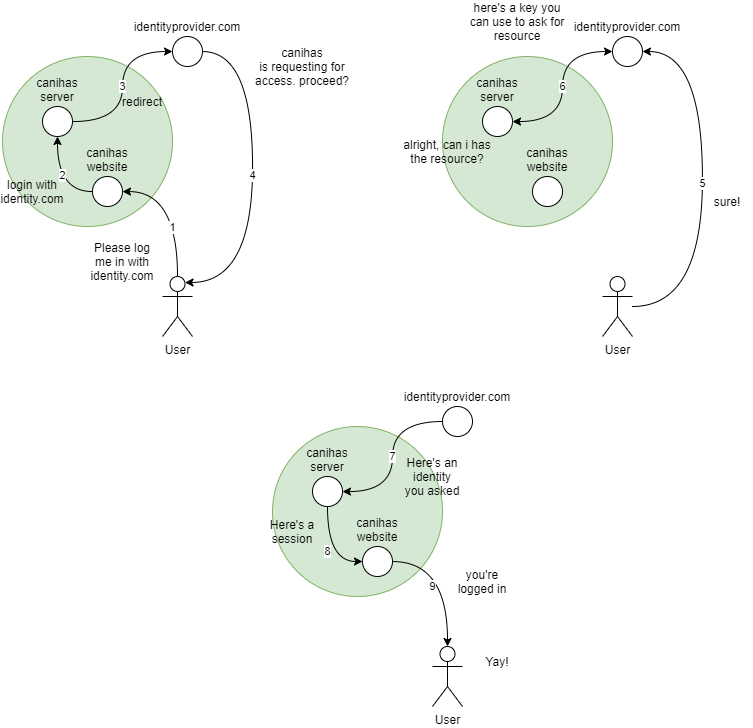
The whole loop is simplified in step 6. In step 3, instead of creating the important value in the backend and saving it on the website's local storage. The server, while asking for the authorization code to Identity Provider, passed the important value too in the state field, encrypted. The Identity Provider OAuth client configuration is set to redirect back to a specific endpoint on the server instead of the website. The server then gets the value back from the state field that is passed around the Identity Provider. This way, the website does not need to know about the authorization code flow at all and we can cut a lot of risk of potential maintenance in the future.
Other random tips
Freeze a Tree in time
One trick I learned during my journey as a programmer: Freeze a tree in time.
A Complex function can be overlong. Littered with branches, loops, and mutable references, complex functions take extra effort to read. The existence of mutable references implicitly renders the function to be mesh-shaped, because at any point in the scope, that reference can be read and written, a phenomenon similar to a side-effect. Long branches and loops can be extracted to another function that returns a sum data type. Sum data types can act as frozen branches and loops.
Several languages also support complex expressions, like block expressions or self-executing anonymous functions. These features can be used in conjunction with sum data type to eliminate long branches and loops and mutable references.
// For functions with several branches
// Converge it into a sum type
// Each branch results in a return
struct ConnectFailed = Error.extend("ConnectFailed", unknown);
struct ServerError = Error.extend("ServerError", HttpReponsePayload);
struct ClientError = Error.extend("ClientError", HttpReponsePayload);
struct DecodeError = Error.extend("DecodeError", string);
struct OtherError = Error.extend("OtherError", unknown);
type Errors =
| DecodeError
| ConnectFailed
| ServerError
| ClientError;
// This function is in the shape of a tree
const requestSomething = (): Either<Errors, Something> => {
const result = request();
if (!isLeft(result)) {
return left(ConnectFailed.new(result.left));
}
const responsePayload = result.right;
match {
Http2xx.is(responsePayload.httpStatusCode) => {
const raw = responsePayload.body;
const maybeSomething = Something.tryFrom(raw);
if (isLeft(maybeSomething)) {
return left(DecodeError.new(raw));
}
return right(maybeSomething.right);
}
Http4xx.is(responsePayload.httpStatusCode) => {
return left(ClientError.new(responsePayload));
},
Http5xx.is(responsePayload.httpStatusCode) => {
return left(ServerError.new(responsePayload));
}
default => {
return left(OtherError.new(responsePayload));
}
}
}
// The function above can be used this way
const loadSomethingAndHandle = () => {
const maybeSomething = requestSomething();
if (isLeft(maybeSomething)) {
notifyError(maybeSomething)
}
show(maybeSomething)
}
// IN CONTRAST
// here's an alternative with mutable reference
// It is harder to parse by eye
const loadSomethingAndHandle = () => {
// like JavaScript's let, this binding is mutable and nullable
let maybeSomething = null;
const result = request();
if (!isLeft(result)) {
maybeSomething = left(ConnectFailed.new(result.left));
}
const responsePayload = result.right;
match {
Http2xx.is(responsePayload.httpStatusCode) => {
const raw = responsePayload.body;
const maybeSomething = Something.tryFrom(raw);
maybeSomething =
isLeft(maybeSomething) ?
left(DecodeError.new(raw)) :
right(maybeSomething.right);
}
Http4xx.is(responsePayload.httpStatusCode) => {
maybeSomething = left(ClientError.new(responsePayload));
},
Http5xx.is(responsePayload.httpStatusCode) => {
maybeSomething = left(ServerError.new(responsePayload));
}
default => {
maybeSomething = left(OtherError.new(responsePayload));
}
}
// An extra type check
// maybeSomething is mutable, initialized as null
// This can be eliminated by making maybeSomething
// an immutable reference capturing an expression
if (maybeSomething === null) {
notify("Error, this should never happen")
return;
}
if (isLeft(maybeSomething)) {
notifyError(maybeSomething)
}
show(maybeSomething)
}
Since sum type is a programming language feature, using it is essentially letting the compiler do the work. And letting the compiler do the work is a smart move because it's probably more correct than if you're doing it by yourself and also "Your compile-time is someone's runtime" (Unfortunately I don't remember where exactly I read this quote so I can't give proper credit. Whoever invented it, you're awesome)
Own Every Data
A function that owns references and statements has more control over those. Having control over several references and statements means that you can easily insert, remove, and reorder the executions of the references and statements.
// EXAMPLE 1. THE RIGHT ONE
function some_important_function(param) {
const config = initialize(param);
const result = do_some_heavy_calc(config)
print(result);
}
function initialize(param) {
return some_initialization(param);
}
function do_some_heavy_calc(config){
return some_heavy_calc_impl(config);
}
In contrast, this is the fire-and-forget pattern. I recommend avoiding this pattern because, opposite to the effect of having all references and statements in one function, this pattern is much harder to reorder, insert, and remove.
// EXAMPLE 2. THE NOT QUITE RIGHT ONE
// You might think "why would you this?"
// But I've seen people do this all the time.
function some_important_function(param) {
initialize(param);
}
function initialize(config) {
do_some_heavy_calc(config)
}
function do_some_heavy_calc(config) {
print(some_heavy_calc_impl(config))
}